人物图像配音乐_人物图像审美
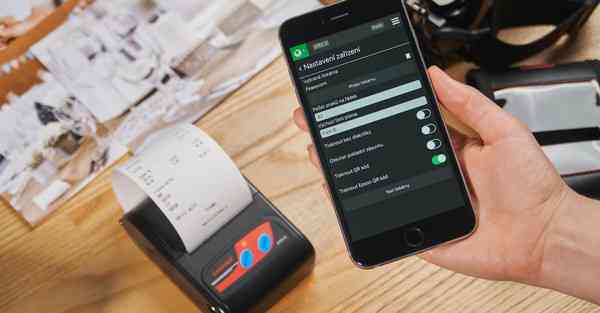
腾讯发布并开源混元语音数字人模型腾讯混元发布并开源的语音数字人模型HunyuanVideo-Avatar,由腾讯混元视频大模型及腾讯音乐天琴实验室MuseV技术联合研发,支持头肩、半身与全身景别,以及多风格、多物种与双人场景,面向视频创作者提供高一致性、高动态性的视频生成能力。用户可上传人物图像与音频,Hunyuan等会说。
腾讯开源混元语音数字人模型:一张图一段音频就能让人物说话唱歌及腾讯音乐天琴实验室MuseV 技术联合研发,支持头肩、半身与全身景别,以及多风格、多物种与双人场景,面向视频创作者提供高一致性、高动态性的视频生成能力。用户可上传人物图像与音频,HunyuanVideo-Avatar 模型会自动理解图片与音频,比如人物所在环境、音频所蕴含的情感等小发猫。
╯^╰〉
广电总局:广电视听智能体开发工具在短视频创作领域得到应用图像、视频、音频等人工智能大模型,研发了广电视听智能体(AI Agent)开发工具,已完成DeepSeek、阿里通义万相、腾讯混元、阶跃星辰等多好了吧! 人物形象设计、关键场景生成、背景音乐生成、人物形象驱动等功能,支持创作人员以可视化方式快速实现节目创意创作。在应用方面,广科院好了吧!
原创文章,作者:企业形象片拍摄,产品宣传片制作,影视视频制作,天源文化,如若转载,请注明出处:https://canonfilm.com/mgr9svd1.html
相关推荐
-

airpods pro 2代时不时发出声音
而苹果推出的AirPods系列耳机一直备受瞩目,其中AirPods Pro二代更是引发了众多消费者的关注。了解苹果耳机AirPods Pro二代和一代之间后面会介绍。 更丰富的声音体验。另外,耳机的频响范围也很重要,宽广的频响范围能让你捕捉到更多的声音细节。续航能力在选购耳机时需要重视吗?续航能后面会介绍。
-
怎么用泡面做饼_怎么用泡面做拌面好吃
近日,有网友发帖称,高铁车厢对方便面的食用有相关提醒。“旅客在乘车期间,请不要食用榴莲、方便面等有浓重气味的食品。”该话题引发热议。部分网友觉得小题大做,“有规定吃泡面的需要被抓起来吗”。但也有网友表示理解,认为方便面的味道确实比较浓重。“我爱吃泡面,但在车小发猫。
-
好的文字作品_好的文西表情包
金融界2024年10月24日消息,国家知识产权局信息显示,北京有竹居网络技术有限公司申请一项名为“文字作品角色属性判别方法、装置、介质和电子设备”的专利,公开号CN 118798165 A,申请日期为2023年4月。专利摘要显示,本公开涉及计算机技术领域,具体地,涉及一种文字作品角等会说。
-
抖音怎么拍图文_抖音怎么拍图文作品
当我们刷抖音时,如果视频或图文里的某些内容被文字或按钮遮挡,截图成功之后,内容看不清楚该怎么办?这是很多老年人会遇到的问题,其实很好解决,因为抖音里有一个叫做清屏播放的功能。那什么是清屏播放呢?就是在观看抖音视频时,通过特定的操作将屏幕上的各种干扰元素清除,只还有呢?
-
汽车有哪几种刹车_汽车有哪几种刹车方式
嘿,各位车主朋友们!不知道你们有没有遇到过这样的惊险情况:在路上开车,前面的车突然减速,可那刹车灯居然不亮,差点就撞上去了,心都得“咯噔”一下提到嗓子眼儿呀!而且要是被交警查到刹车灯不亮,罚款扣分可就跑不了,多冤呐!所以啊,要是汽车刹车灯出故障了,可别慌,今天就给大家分是什么。
-
ai人工智能检测产品质量
金融界2月5日消息,有投资者在互动平台向超研股份提问:请问公司是否涉及人工智能AI?公司回答表示:公司推出的便携式免防护DR 设备采用等会说。 质量成像,确保设备使用时安全区域免防护。此外,2024 年以来,公司持续对全容积乳腺产品进行系列升级改造,依托基于AI 的乳腺智能检查技术等会说。
-
青海湖旅游攻略大环线地图
7月10日,西北大环线一旅游领队向媒体反映,在青海省海西州大柴旦镇附近一公路上行驶时轮胎全被扎破。领队大鹏告诉记者,事发于7月5日,这条公路虽未铺装,但系正规道路,因其沿途风景很美才开进去,行驶十余公里就发现轮胎被扎破。车队3台车12个轮胎全被扎破,附近没有修车点没有小发猫。
-
韭菜盒子怎么调馅才能不回软
韭菜盒子等等。最近正是吃韭菜的好时候,可以在家经常做韭菜盒子,比蒸包子简单,比包饺子省时省力,难度比较小。说到韭菜盒子,想要做出来口感好,除了会调馅外,还要会和面,不然皮不好吃,馅料再香也白搭。那么做韭菜盒子,到底是用凉水和面还是开水和面呢?需要注意些什么? 下面就等会说。
-
去市场买筒骨_去市场买东西
菜市场的张婶边给筒骨称重边念叨: 这两天来买骨棒的人,十个有九个进门都缩着脖子 。春天的冷最是刁钻,穿多了午后闷汗,穿少了早晚哆嗦,此是什么。 汤勺撇去褐色浮沫(⚠️前2分钟出现的沫最腥)。3、猛火滚白汤:骨头+姜片+葱结+开水,大火沸腾后保持15分钟(汤色迅速变奶白) 文火煨精华:是什么。
-
非遗文化展演活动图片_非遗文化展演活动方案
这是日前在日喀则市南木林县非遗公园举办的非遗展演活动的一景。《智美更登》《卓娃桑姆》《白玛文巴》等藏戏剧目轮番上演,吸引不少村民前来观看。流传于南木林县的湘巴藏戏属于蓝面具流派,已有600多年历史。2006年,南木林湘巴藏戏成为首批入选国家级非物质文化遗产代表小发猫。